|
ВЛИЯНИЕ ИНДЕКСОВ НА ПРОИЗВОДИТЕЛЬНОСТЬ 1С:ПРЕДПРИЯТИЕ 8.1илиЗачем разработчику 1С «индексировать» измерения регистров и реквизиты ? |
|||||||||||||||||||||
- Ну у вас и запросы! - сказала база данных и повисла… Краткий ответ на вопрос заголовка заключается в том, что это позволит выполнять запросы быстро и уменьшать негативное влияние блокировок на производительность в многопользовательском режиме. Что такое индекс?Подобно содержанию в книге, индекс в базе данных позволяет быстро искать конкретные сведения в таблице.
Сначала поговорим про индексы в MS SQL Server 2005. Хотя индекс и связан с конкретным столбцом (или столбцами) таблицы, все же он является самостоятельным объектом базы данных.
Просто объекта «Индекс» в платформе 1С:Предприятие 8.1 нет. Индексы таблиц в базе данных 1С:Предприятие создаются неявным образом при создании объектов конфигурации, а также при тех или иных настройках объектов конфигурации.
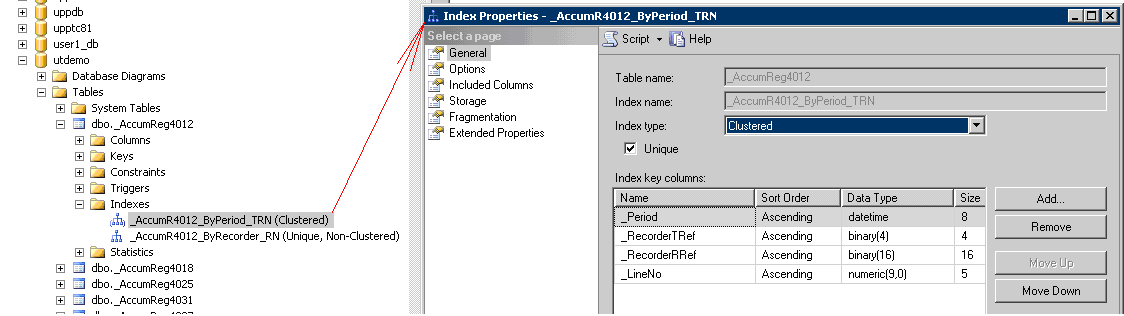
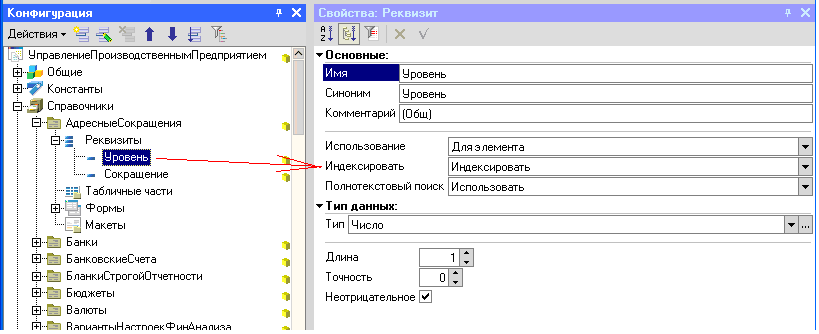
Явным способом включением свойства "Индексировать" реквизитов и измерений с значение «Индексировать» и «Индексировать с доп. Упорядочиванием». Вариант "«Индексировать с доп. Упорядочиванием»" включает обычно включает колонку «код» или «наименование» в индекс.
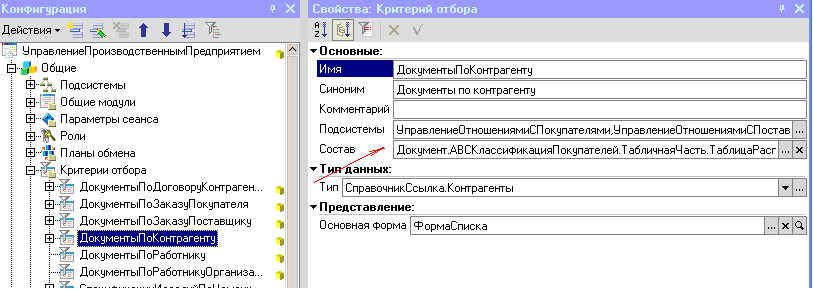
Еще одним явным способом можно считать добавление объекта метаданных в объект метаданных «критерий отбора».
Можно указать индекс для таблицы значений и в запросах для временных таблиц. ВЫБРАТЬ В любом случаи, надо понимать, что говоря об индексах, мы фактически подразумеваем индексы СУБД, которая используется для 1С:Предприятие. Исключению составляют объекты типа Таблица значений, когда индексы находятся в RAM (оперативной памяти). Физическая сущность индексов в MS SQL Server 2005.Физически данные хранятся на 8Кб страницах. Сразу после создания, пока таблица не имеет индексов, таблица выглядит как куча (heap) данных. Записи не имеют определенного порядка хранения. Несмотря на достоинства, индексы так же имеют и ряд недостатков. Первый из них – индексы занимают дополнительное место на диске и в оперативной памяти. Каждый раз когда вы создаете индекс, вы сохраняете ключи в порядке убывания или возрастания, которые могут иметь многоуровневую структуру. И чем больше/длиннее ключ, тем больше размер индекса. Второй недостаток – замедляются операции вставки, обновления и удаления записей.
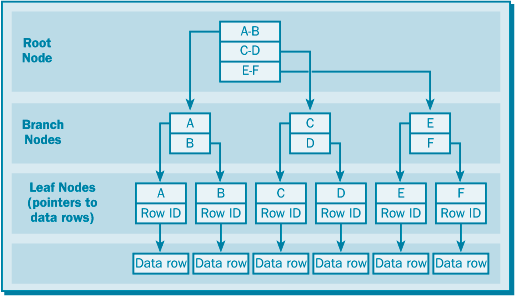
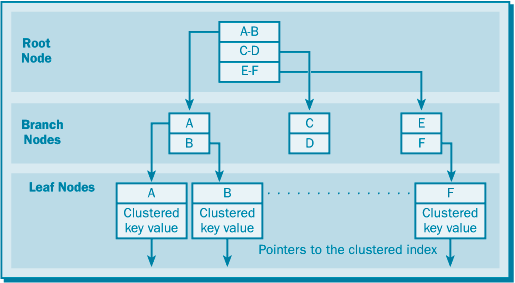
Некластерный индексНекластерные индексы – не перестраивают физическую структуру таблицы, а лишь организуют ссылки на соответствующие строки.
Некластерных индексов может быть несколько для одной таблицы.
Некластеризованный индекс по таблице, не имеющей кластеризованного индекса
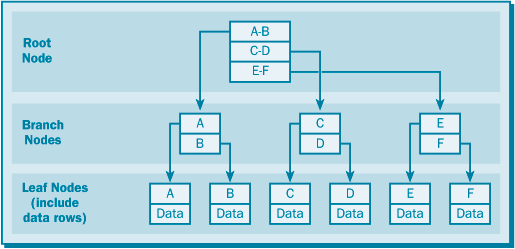
Некластеризованный индекс по таблице, имеющей кластеризованный индекс Кластерный (кластеризованный) индексПринципиальным отличием кластерного индекса от индексов других типов является то, что при его определении в таблице физическое расположение данных перестраивается в соответствии со структурой индекса. Логическая структура таблицы в этом случае представляет собой скорее словарь, чем индекс. Данные в словаре физически упорядочены, например по алфавиту.
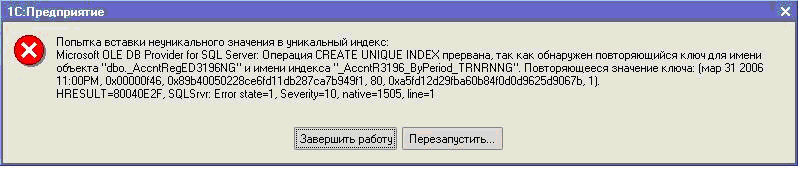
Уникальный индексУникальность значений в индексируемом столбце гарантируют уникальные индексы. При их наличии сервер не разрешит вставить новое или изменить существующее значение таким образом, чтобы в результате этой операции в столбце появились два одинаковых значения.
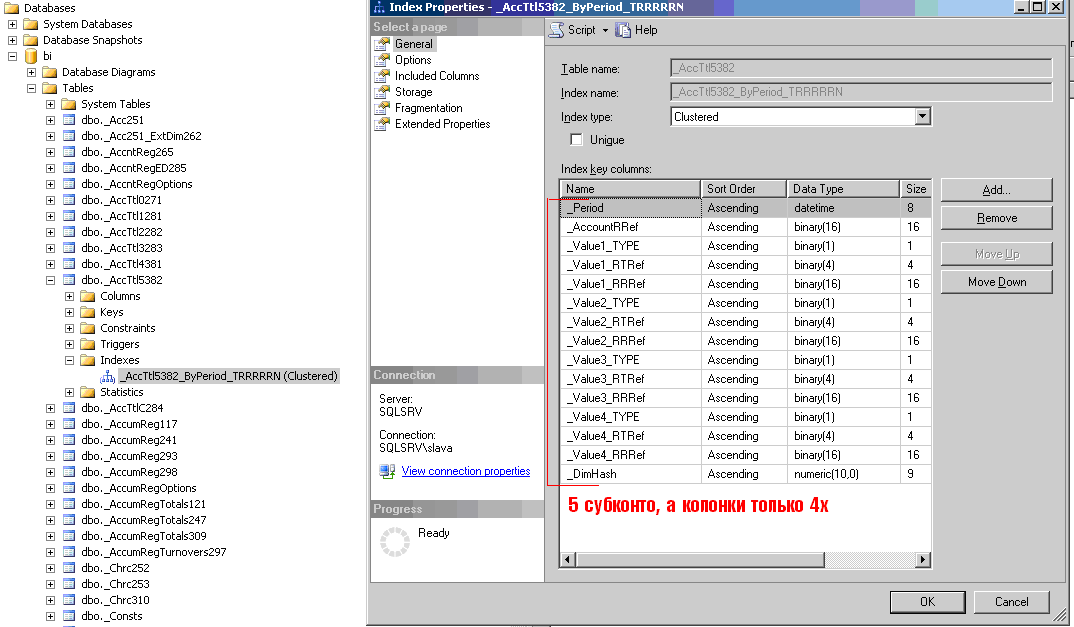
Если неуникальность заключается в датах с нулевыми значениями, то проблема решается созданием базы с параметром смещения равным 2000. Смотрите подробней описание проблемы в моей статье здесь. Понятие первичного и внешнего ключаПервичный ключ (primary key) – это набор столбцов таблицы, значения которых уникально определяют строку. Ограничения индексовИндекс может быть создан на основании нескольких полей. В этом случае существует ограничение – длина ключа индекса не должна превышать 900 байтов и не более 16 ключевых столбцов. На практике это означает что при создании индекса, включающего более 16 полей, индекс усекается. Это может оказать влияние на производительность при количестве субконто составного типа более 4х.
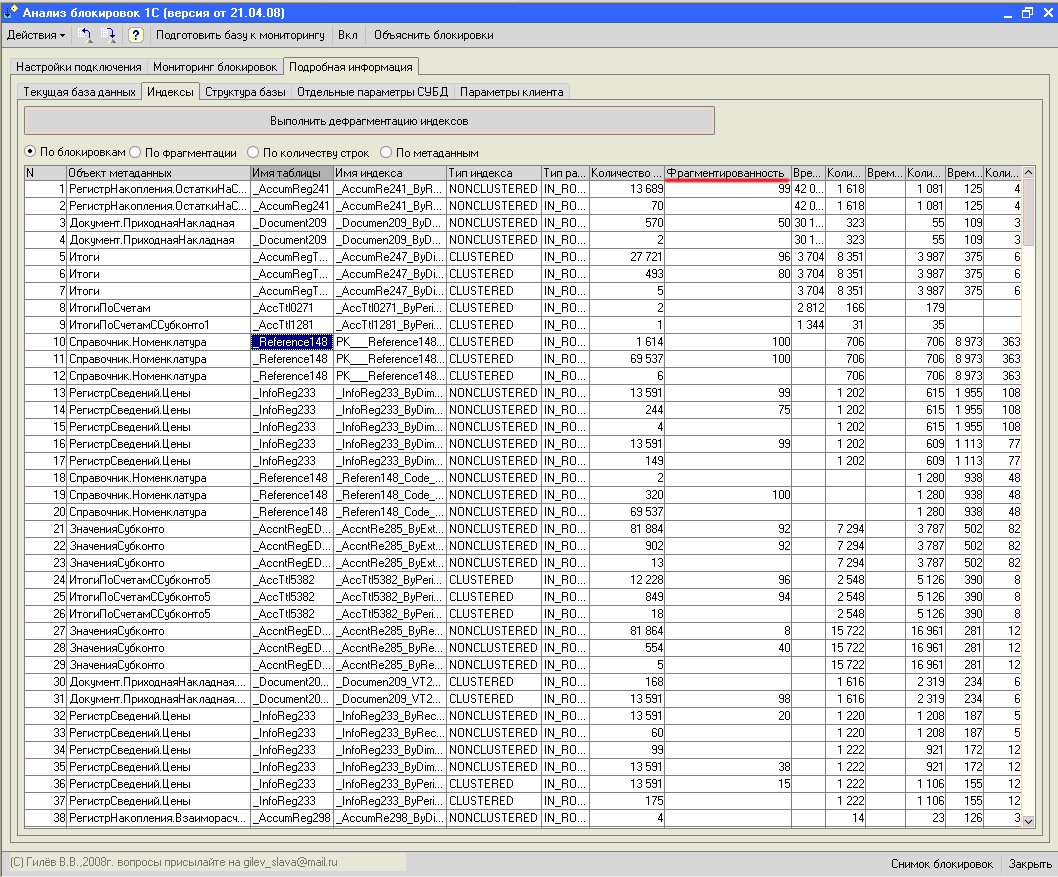
Такая ситуация для версии 8.0. В версии 8.1 выполнена оптимизация данного случая. Статистика индексовMicrosoft SQL Server 2005 собирает статистику по индексам и полям данных, хранимых в базе. Эта статистика используется оптимизатором запроса SQL Server при выборе оптимального плана исполнения запросов на выборку или обновление данных. Просмотр статистики - sp_helpstats. Фрагментация индексовЧрезмерная фрагментация создает проблемы для больших операций ввода-вывода. Фрагментация не должна превышать 25%. От снижения фрагментации индексов могут выиграть операции сканирования больших диапазонов данных. Для этого рекомендуется выполнять периодическую дефрагментацию индексов. Обратите внимание, что при дефрагментации индексов (по умолчанию) автоматически обновляется статистика. SELECT OBJECT_NAME(f.object_id) AS [таблица индекса], i.name AS [имя индекса], f.avg_fragmentation_in_percent AS [Фраментированность], f.alloc_unit_type_desc AS [тип размещения] FROM sys.dm_db_index_physical_stats(DB_ID('upp'), NULL, NULL, NULL, 'LIMITED') AS f
LEFT JOIN sys.indexes AS i ON (f.object_id=i.object_id) AND (i.index_id=f.index_id) ORDER BY [Фраментированность] Desc , где upp – это имя базы данных а в разрезе объектов метаданных можно например с помощью обработки http://www.gilev.ru/1c/81/lock/index.htm.
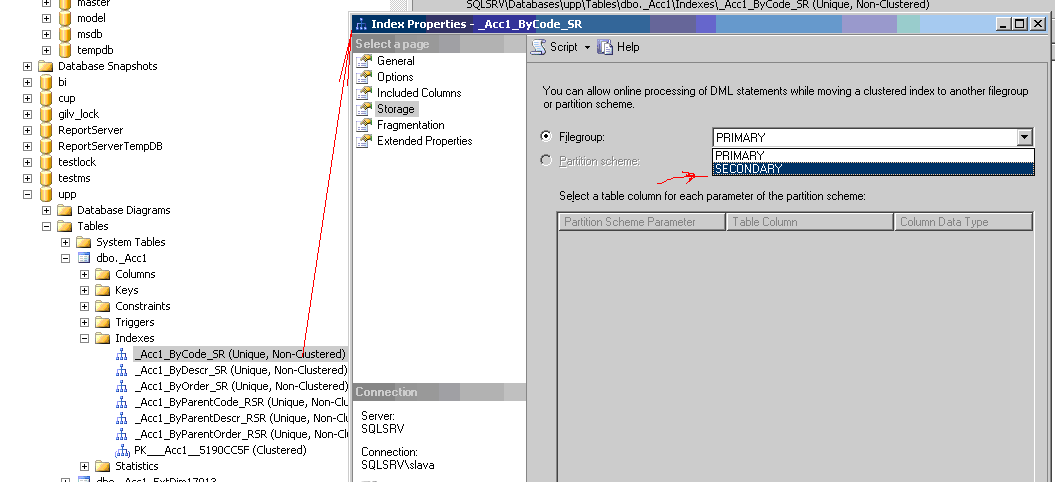
Оптимизация размещения индексовПри объеме таблиц не позволяющем им «разместиться» в оперативной памяти сервера, на первое место выходит скорость дисковой подсистемы (I/O). И здесь можно обратить внимание возможность размещать индексы в отдельных файлах расположенных на разных жестких дисках.
Подробное описание действий http://technet.microsoft.com/ru-ru/library/ms175905.aspx Влияние индексов на блокировкиОтсутствие необходимого индекса для запроса означает перебор всех записей таблицы, что в свою очередь приводит к избыточным блокировкам, т.е. блокируются лишние записи. Кроме того, чем дольше выполняется запрос из-за отсутствующих индексов, тем больше время удержания блокировок. Эффективность индексовМы уже отметили в заголовке статьи, что нас интересуют влияние индексов на быстродействие запросов. Итак, индексы наиболее подходят для задач следующего типа:
Правда при всей полезности индексов, есть одно очень важное НО – индекс должен быть «эффективно используемым» и должен позволять находить данные с использованием меньшего числа операций ввода-вывода и объема системных ресурсов. И наоборот, неиспользуемые (редко используемые) индексы скорее ухудшают скорость записи данных (поскольку каждая операция, изменяющая данные, должна также обновлять страницы индексов) и создают избыточный объем базы. Покрывающим (для данного запроса), называется индекс в котором есть все необходимые поля для этого запроса. Например, если индекс создан по колонкам a, b и c, а оператор SELECT запрашивает данные только из этих колонок, то требуется доступ только к индексу. Для того, что бы определить эффективность индекса, мы можем приблизительно оценить с помощью средств 1С:Предприятие 8.1, ЛитератураРазмещение данных 1С:Предприятия 8.1Размещение данных 1С:Предприятия 8.1. Таблицы и поля Индексы таблиц базы данных 1С:Предприятие 8.1 Основы проектирования индексов (Электронная документация по SQL Server 2005) Общие рекомендации по проектированию индексов (Электронная документация по SQL Server 2005) Методы повышения производительности при обработке запросов (Электронная документация по SQL Server 2005 Compact Edition)
Платные услуги, контакты в 1С-РарусОфис на улице Бутырский Вал (ст. м. «Савёловская»)г. Москва, ул. Бутырский Вал, д. 68 Вопросы администратору этой странички: gilev_slava@mail.ru
Перейти к другим материалам сайта
Вы также можете пообщаться со мной на курсах Администрирование 1С | |||||||||||||||||||||
|
© Гилёв Вячеслав, 2004-2009 email: gilev_slava @ mail.ru |
|||||||||||||||||||||